https://github.com/ageron/handson-ml3/blob/main/01_the_machine_learning_landscape.ipynb
2006年,Geoffrey E. Hinton 等人发表了一篇论文,展示了如何训练能够以最高的精度(>98%)来识别手写数字的深度神经网络。他们将这种技术称为深度学习。
稍微通用一点的定义:机器学习是一个研究领域让计算机无须进行明确编程就具备学习能力。——亚瑟·塞缪尔(Arthur Samuel),1959
更工程化的定义:一个计算机程序利用经验E来学习任务T,性能是P,如果针对任务T的性能P随着经验E不断增长,则称为机器学习。——汤姆·米切尔(Tom Mitchell),1997
例如,垃圾邮件过滤器就是一个机器学习程序,它可以根据给定的垃圾邮件(由用户标记)和普通电子邮件(非垃圾邮件,也称为ham)学习标记垃圾邮件。系统用来学习的样例称为训练集。每个训练样例称为训练实例(或样本)。机器学习系统中学习和做出预测的部分称为模型。例如,神经网络和随机森林
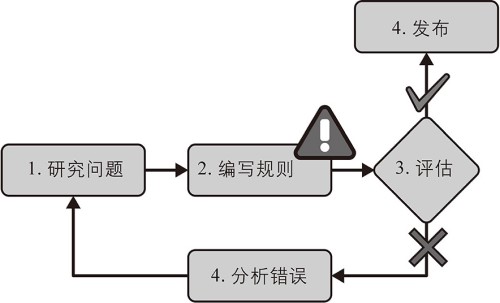
代码程序写一些死的规则,关键词判断,内容长短等等。
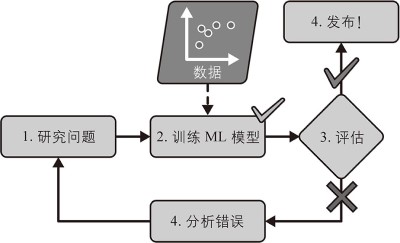
从大量数据集中寻找规律,用经验规律判定新的数据,进行分类等。
定义:通过已标记的训练数据学习一个函数,将输入映射到输出。
特点: - 需要大量带标签的训练数据 - 有明确的目标输出 - 学习过程是通过最小化预测值与真实值之间的误差
常见算法: - 分类:逻辑回归、决策树、SVM、KNN、随机森林、神经网络 - 回归:线性回归、多项式回归、决策树回归、神经网络回归
应用场景: - 图像分类 - 垃圾邮件检测 - 情感分析 - 预测房价 - 医疗诊断
优缺点: - 优点:准确度高,理论成熟,可解释性强 - 缺点:需要大量标记数据,可能过拟合,标注成本高
定义:从无标签数据中发现隐藏的模式或结构。
特点: - 不需要标记数据 - 目标是发现数据内在结构 - 没有明确的输出指导
常见算法: - 聚类:K-Means、层次聚类、DBSCAN、高斯混合模型 - 降维:PCA、t-SNE、LDA、自编码器 - 异常检测:单类SVM、隔离森林 - 关联规则学习:Apriori算法
应用场景: - 客户分群 - 特征提取 - 推荐系统 - 异常检测 - 市场篮子分析
优缺点: - 优点:不需要标记数据,可发现隐藏模式 - 缺点:评估困难,结果解释复杂,准确性不易衡量
定义:结合少量标记数据和大量未标记数据进行学习。
特点: - 同时使用标记和未标记数据 - 减少对标记数据的依赖 - 充分利用未标记数据提供的信息
主要方法: - 自训练 (Self-training) - 协同训练 (Co-training) - 图方法 (Graph-based methods) - 半监督SVM - 生成式方法
假设基础: - 平滑假设:相似的样本应有相似的输出 - 聚类假设:数据倾向于形成离散的聚类 - 流形假设:高维数据分布在低维流形上
应用场景: - 文本分类 - 语音识别 - 医学图像分析 - 网页分类
优缺点: - 优点:减少标注成本,性能优于纯监督(数据少时) - 缺点:实现复杂,假设不成立时可能导致性能下降
定义:从数据本身自动生成监督信号,无需外部标签。
特点: - 自动创建”伪标签” - 利用数据内在结构和关系 - 预训练-微调范式
常见技术: - 上下文预测 - 对比学习 - 掩码预测 - 生成式预训练
代表模型: - BERT(掩码语言模型) - GPT(自回归语言模型) - SimCLR(对比学习) - MAE(遮罩自编码器)
应用场景: - 自然语言处理 - 计算机视觉 - 语音识别 - 多模态学习
优缺点: - 优点:极大减少标注需求,可学习强大表示 - 缺点:计算成本高,任务设计复杂
定义:通过与环境交互并从反馈中学习,最大化累积奖励。
核心元素: - 智能体 (Agent) - 环境 (Environment) - 状态 (State) - 动作 (Action) - 奖励 (Reward) - 策略 (Policy)
主要方法: - 基于值的方法:Q-Learning、DQN - 基于策略的方法:REINFORCE、PPO - 演员-评论家方法:A2C、A3C、DDPG - 模型为基础的方法:AlphaGo、MuZero
探索与利用: - ε-贪心策略 - 玻尔兹曼探索 - UCB(上置信界) - 参数噪声
应用场景: - 游戏AI - 机器人控制 - 自动驾驶 - 资源分配优化 - 推荐系统
优缺点: - 优点:可解决复杂顺序决策问题,适应动态环境 - 缺点:样本效率低,收敛慢,超参数敏感
定义:一次性使用所有可用数据进行训练,模型训练完成后不再更新。
特点: - 离线学习 - 一次性处理所有数据 - 需要重新训练以适应新数据
实现步骤: 1. 收集所有训练数据 2. 数据预处理和特征工程 3. 模型训练和评估 4. 部署模型 5. 当需要更新时,重新训练整个模型
适用场景: - 数据规模适中 - 数据分布相对稳定 - 计算资源充足 - 模型不需频繁更新
优缺点: - 优点:实现简单,可多次遍历数据,易于调优 - 缺点:不适应数据变化,重训练成本高,延迟大
定义:模型通过连续数据流逐步学习,能够实时更新。
特点: - 增量学习 - 实时处理数据 - 持续适应新模式
常见方法: - 随机梯度下降 - 被动攻击 - 在线贝叶斯方法 - 在线决策树
实现步骤: 1. 初始化模型 2. 接收新数据实例 3. 用新数据更新模型 4. 丢弃数据或选择性存储 5. 重复步骤2-4
适用场景: - 流数据分析 - 时间序列预测 - 推荐系统 - 金融交易 - IoT数据处理
优缺点: - 优点:适应变化数据,内存高效,实时响应 - 缺点:噪声敏感,可能遗忘旧模式,难以调优
| 学习方式 | 数据需求 | 主要特点 | 适用场景 | 计算复杂度 |
|---|---|---|---|---|
| 监督学习 | 标记数据 | 直接学习输入-输出映射 | 分类、回归 | 中等 |
| 无监督学习 | 无标记数据 | 发现数据结构 | 聚类、降维 | 中等到高 |
| 半监督学习 | 少量标记+大量无标记 | 结合标记与无标记数据 | 数据标注昂贵场景 | 高 |
| 自监督学习 | 无标记数据 | 自动生成监督信号 | 表示学习、预训练 | 高 |
| 强化学习 | 环境交互数据 | 通过奖励信号学习 | 顺序决策问题 | 非常高 |
| 批量学习 | 静态数据集 | 一次性处理所有数据 | 稳定环境 | 与数据规模成比例 |
| 在线学习 | 数据流 | 实时、增量处理 | 动态环境 | 较低(每步) |
这些学习方式各有优缺点,在实际应用中常常结合使用以发挥各自优势。
线性回归小样例
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# Download and prepare the data
# https://github.com/ageron/data/blob/main/lifesat/lifesat.csv
lifesat = pd.read_csv("lifesat.csv")
# 人均GDP
X = lifesat[["GDP per capita (USD)"]].values
# 生活满意度
y = lifesat[["Life satisfaction"]].values
# Visualize the data
lifesat.plot(kind='scatter', grid=True,
x="GDP per capita (USD)", y="Life satisfaction")
plt.axis([23_500, 62_500, 4, 9])
plt.show()
# Select a linear model
model = LinearRegression() # 线性回归模型
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[37_655.2]] # Cyprus' GDP per capita in 2020
print(model.predict(X_new)) # outputs [[6.30165767]]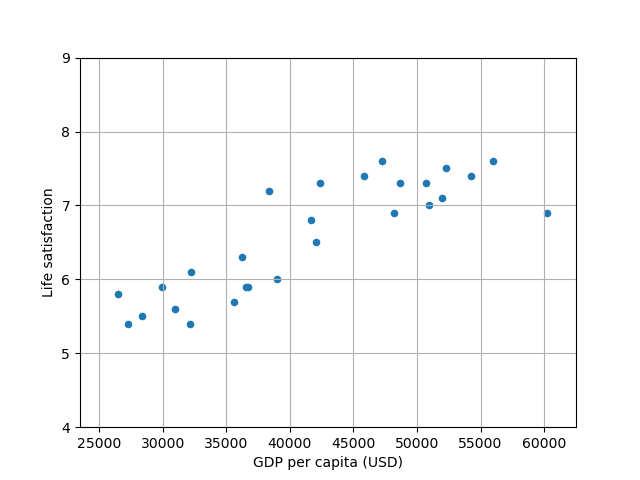
可以把上面的换成K近邻模型
import sys
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsRegressor
# Download and prepare the data
lifesat = pd.read_csv("lifesat.csv")
# 人均GDP
X = lifesat[["GDP per capita (USD)"]].values
# 生活满意度
y = lifesat[["Life satisfaction"]].values
# Visualize the data
lifesat.plot(kind='scatter', grid=True,
x="GDP per capita (USD)", y="Life satisfaction")
plt.axis([23_500, 62_500, 4, 9])
plt.show()
# Select a linear model
model = KNeighborsRegressor(n_neighbors=3) # K近邻
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[37_655.2]] # Cyprus' GDP per capita in 2020
print(model.predict(X_new)) # outputs [[6.30165767]]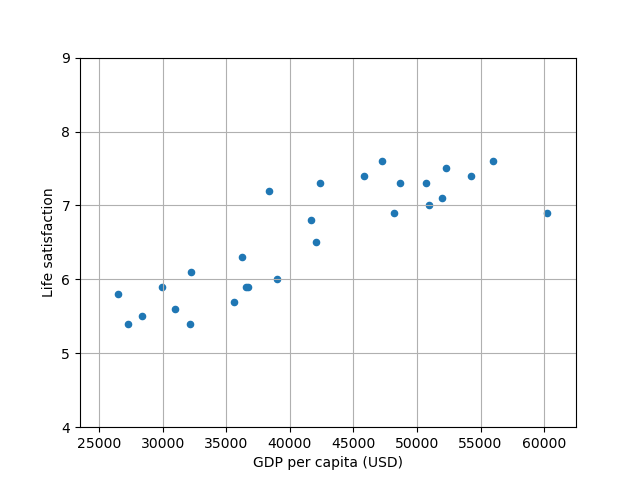
数据量不足会导致模型无法准确捕捉目标函数的特征。对于复杂问题,深度学习等需要大量数据的算法性能会受到严重影响。解决方法包括:数据增强、迁移学习、使用预训练模型,或选择对小数据集更友好的算法如支持向量机。
当训练数据无法准确代表实际应用场景的数据分布时,模型将产生系统性偏差。例如,仅用特定地区人群图像训练的人脸识别系统可能对其他种族表现不佳。解决方案包括:确保样本多样性、进行分层采样、识别并填补数据分布中的空白。
数据中的噪声、不平衡和缺失值会严重影响模型性能:
解决方法包括:数据清洗、过采样/欠采样、SMOTE等平衡技术、缺失值插补。
模型输入中包含与预测目标无关的特征会引入噪声,增加过拟合风险并降低模型解释性。应用特征选择技术(过滤法、包装法、嵌入法)、正则化,或使用主成分分析(PCA)等降维技术可以有效解决这一问题。
过拟合指模型在训练数据上表现极佳,但无法泛化到新数据。常见解决方法包括:
欠拟合发生在模型过于简单,无法捕捉数据中的关键模式时。解决方法包括:
微调是优化已训练模型性能的过程,包括:
有效的测试与验证至关重要,确保模型性能评估可靠:
正确划分训练集和测试集对可靠评估模型至关重要:
有效的超参数调整对最终模型性能至关重要:
训练数据与实际应用环境数据分布不同会导致模型性能下降:
该定理表明不存在在所有可能问题上都表现最佳的通用算法。关键含义: